
The Full Information to Robots.txt and Noindex Meta Tag

The Robots.txt file and Noindex meta tag are important for doing on-page SEO. This gives you the power to tell Google which pages they should crawl and which pages they should index – display in the search results.
Knowing how to use these two and when to use them is important for all SEOs since this involves a direct relationship between the websites we’re handling and the search engine crawlers. Being able to direct the search engine crawlers on where they should go and which pages they should include in the database is a massive advantage for us, and we can use that to make sure that only our website’s important pages are the ones that Google and other search engines crawl and index. But before we delve into the details of how and when to use these two, we must first know what they are and their specific functions.
What is a Robots.txt file?
The Robots Exclusion Protocol, or more commonly known as Robots.txt is a file that directs web crawlers and robots such as Googlebot and Bingbot to which pages of your websites should not be crawled.
What is the use of a Robots.txt file?
The robots.txt file is only a crawling directive and it cannot control how fast a bot should crawl your website and other bot behaviors. This is just a set of instructions for bots on what parts of your website should not be accessed.
You should also take note that while some bots respect robots.txt file, some can ignore it. Some robots can exploit files on your website or even harvest information so to completely block malware robots, you should increase your site security or protect private pages by putting a password. If you have other questions about the robots.txt, check out some frequently asked questions on robots here.
How to Create a Robots.txt File?
By default, a robots.txt file would look like this:
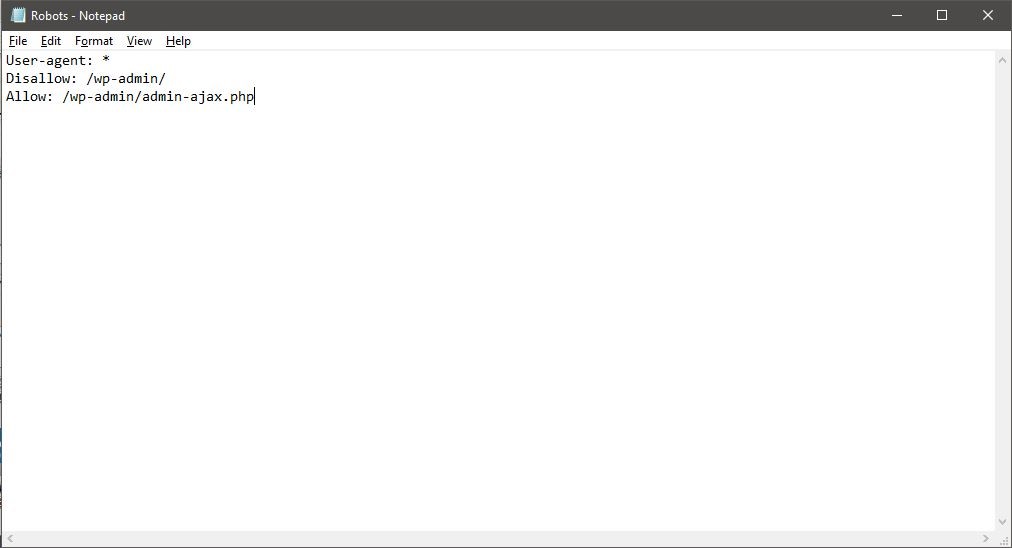
You could create your own robots.txt file in any program that is in .txt file type. You could block different URLs such as your website’s blog/categories or /author pages. Blocking pages like this would help bots prioritize important pages on your website more. The robots.txt file is a great way of managing your crawl budget.
Robots crawling directives
| User-agent | Specifies the crawl bot you want to block from crawling a URL eg. Googlebot, Bingbot, Ask, Yahoo. Here’s a link to a directory of known web crawlers |
| Disallow | Specifies URL and all other URLs under it should be blocked |
| Allow | This is only followed by Googlebot. It tells it page can be crawled even if the parent page is disallowed |
| Sitemap | Specifies the location of your website’s sitemap |
Proper usage of wildcards
In the robots.txt, a wildcard, represented as the symbol, can be used as a symbol for any sequence of characters.
A directive for all types of crawl bots:
User-agent:*
The wildcard could also be used to disallow all URLs under the parent page except for the parent page.
User-agent:*
Disallow: /authors/*
Disallow: /categories/*
This means all page URLs under the main author page and categories page are blocked except for them.
A good example of a robots.txt file would look like this
User-agent:*
Disallow: /testing-page/
Disallow: /account/
Disallow: /checkout/
Disallow: /cart/
Disallow: /products/page/*
Disallow: /wp/wp-admin/
Allow: /wp/wp-admin/admin-ajax.php
Sitemap: yourdomainhere.com/sitemap.xml
After editing your robots.txt file, you should upload in the top-level directory of your website’s code so when a bot enters your website for crawling, it would see the robots.txt file first.
What is Noindex?
Noindex is a meta robots tag that tells search engines not to include a page in the search results.
How to Implement Noindex Meta Tag?
There are three ways to put a noindex tag on pages you don’t want search engines to index:
Meta Robots Tag
In thesection of the page, place the following code:
The code may vary depending on your decision. The code mentioned tells all types of crawl bots from indexing a page. Alternatively, if you only want to noindex a page from a specific crawl bot, you could place the name of that bot in the meta name.
To prevent Googlebot from indexing a page:
To prevent Bingbot from indexing a page:
You can also instruct bots to follow or don’t follow links that are found on the page you noindexed.
To follow links in the page:
To tell bots to not crawl the links in the page:
X-Robots-Tag
The x-robots-tag allows you to control the indexing of a page in the HTTP response header of the page. The x-robots-tag is similar to the meta robots tag but it also allows you to tell search engines not to show specific file types in the search results such as images and other media files.
To do this, you need to have access to your website’s .php, .htaccess, or server access file. Directives in the meta robots tag are also applicable to the x-robots-tag. Here’s a great article about the X-Robots-Tag in HTTP headers.
Through YoastSEO
If you’re using YoastSEO in WordPress, there is no need for you to manually place these codes. Just go to the page or post you want to noindex, scroll down to the YoastSEO interface, go to the settings of the post by clicking the gear icon and then select “No” under “Allow Search Engines to Show this Post in Search Results?”

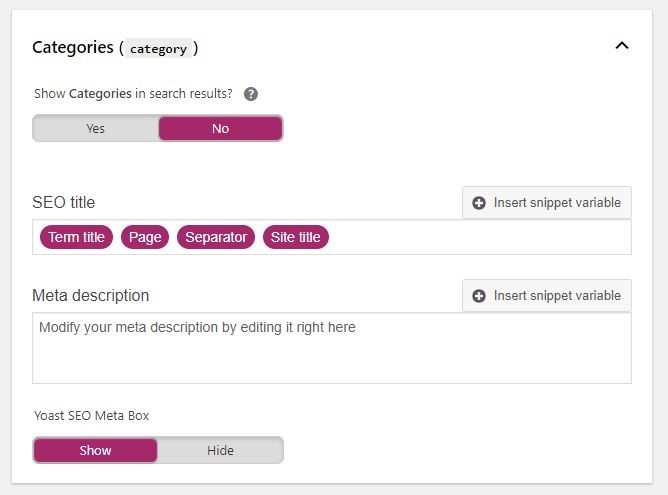
You could also put a noindex tag sitewide for pages such as categories, tags, and author pages so you don’t have to go to every individual page on your website. To put a noindex tag, go to the Yoast plugin itself and then go to Search Appearance. Selecting ‘no’ under ‘Show Categories in Search Results’ would place a noindex tag on all category pages.
Best Practices
Many people are still confused by these two. It is critical as an SEO to know what the difference is in between. This is crucial in making sure that the pages that you want the users to see in the search results are the only pages that appear and the pages you want bots to crawl are the only pages that get crawled.
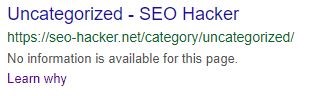
- If you want a page that already has been indexed, for example, by Google, be removed in the search results, make sure that page is not disallowed in the robots.txt file before you add the noindex tag because the Google bot won’t be able to see the tag in the page. Blocking a page without the noindex tag first would still make a page appear in the search results but it would look like this:
- Adding a sitemap directive to the robots.txt file is technically not required, but it is generally good practice.
- After updating your robots.txt file, it is a good idea to check if your important pages are blocked from crawling using the Robots.txt Tester in the Google Search Console.
- Use the URL inspection tool in Google Search Console to see the indexing status of the page.
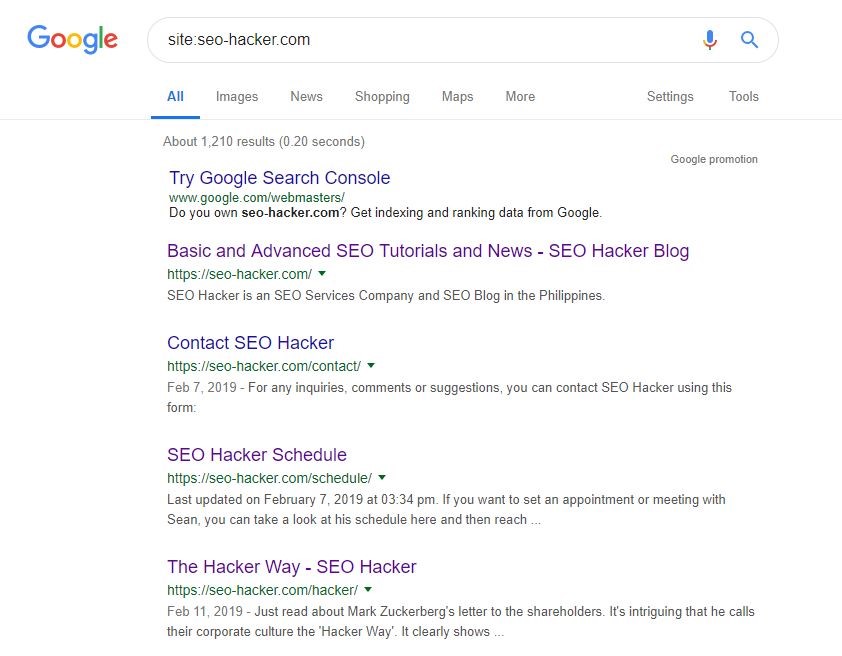
- You can also check for unimportant pages being indexed by Google using the coverage report in Google Search Console. Another alternative would be using the ‘site:’ search command in Google to show you all pages that are being shown in the search results.
Adding Noindex in Robots.txt
There has been a lot of confusion in the SEO community recently about using noindex in the robots.txt but it has been said over and over by Google that they don’t support this but still a lot of people insist that it is still working.
In a Twitter thread, Gary Illyes said:
“Technically, robots.txt is for crawling. The meta tags are for indexing. During indexing, they’d be applied at the same stage so there’s no good reason to have both of them.”
It is best to avoid doing this. While it could be agreed that it is efficient since you don’t have to put a ‘noindex’ tag in individual pages rather just type them in the robots.txt file, it’s better that you treat these two things separately.
Blocked Paged can Still be Indexed if Linked to
In an article by Search Engine Journal, they quoted John Mueller in a Google Hangouts Session. Here’s his statement:
“One thing to maybe keep in mind here is that if these pages are blocked by robots.txt, then it could theoretically happen that someone randomly links to one of these pages and if they do that, it could happen that we index this URL without any content because it’s blocked by robots.txt. So we wouldn’t know that you want to have these pages actually indexed.”
This statement is huge since it gives us a better understanding of how crawl bots and the robots.txt work. This means that pages you blocked through robots.txt is not safe from indexing as long as someone linked to it.
To make sure a page without useful content won’t appear in the search results accidentally, John Mueller suggests that its still better to have a noindex meta tag in those page even after you blocked them from crawl bots with robots.txt
For John Mueller’s full thoughts on this, check out this Google Webmaster Central office-hours hangout back in 2018
Key Takeaway
There are many SEO hacks out there but you have to pick the ones that will give you optimal benefits in the long run. Using your robots.txt file to your advantage will do more than just increase your SEO visibility, it will also improve user experience as well. Robots.txt will stay significant so you have to be on guard for updates which will affect it.
Robots.txt should never be neglected, especially if you want to appear at your best in the SERPs. Brush up on these best practices whether you are a beginner in SEO or you have already optimized many sites. Once you do, you’re going to see how it will help you be cut off from the rest.
With that, comment down below how you use the meta robot tags. How is it working for you so far?